
Etichettato: chatgpt
Il mondo dietro il mondo dell’intelligenza artificiale
Sarà capitato anche a voi di chiedervi quali misteriosi sentieri percorra il vostro smartphone o il vostro pc quando scodella bella e pronta sui vostri schermi la risposta alla domanda che avete posto al vostro assistente digitale, più o meno intelligente. Se non vi è capitato, allora appartenete a quella ampia categorie di persone che se ne infischiano, e che quindi sono i candidati ideali per quel brave new world che si sta organizzando per noi.
Se invece ve lo siete chiesto, appartenete alla categoria dei problematici che sono la croce e la delizia della nostra società, perché sono quelli che si interrogano, che indagano, che studiano, che ricostruiscono: i cercatori.
In questo caso accoglierete con curiosità un bel paper, che peraltro ha il pregio di essere anche breve, pubblicato nei giorni scorsi dalla Bis di Basilea che compie una interessante ricognizione sulla supply chain che anima l’intelligenza artificiale. Ci illustra, per ferla semplice, il mondo che abita dietro il mondo che appare sul vostro schermo.
Lettura consigliatissima, dunque, perché finalmente si mette a fuoco in maniera organica la filiera di produzione, e quindi di interessi, che sta animando questa ennesima rivoluzione industriale, purtroppo ancora troppo poco compresa.
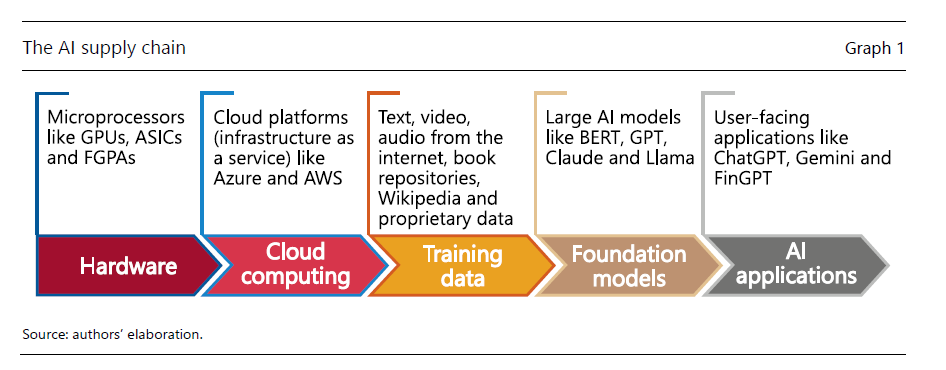
Il grafico sopra schematizza i diversi livelli attraverso i quali viene costruita la risposta alla domanda che voi ponete all’assistente IA. Che possono sembrare ovvi, ma non lo sono affatto.
Il primo, ovviamente, è quello hardware. Per far funzionare questa applicazioni servono chip speciali, come i field-programmable gate arrays (FPGAs), le application-specific integrated circuits (ASICs) e le GPUs. Si tratta di strumenti che consentono l’elaborazione dei dati in parallelo, che in qualche modo simula quello che si pensa faccia il nostro cervello. Fra questi componenti, quelli più usati sono le GPUs. Addestrare un modello IA, tipo un large language models (LLMs) capace di generare testi, richiede centinaia se non migliaia di questi chip. Per dare un’ordine di grandezza, si stima che il motore di ricerca Bing di Microsoft abbia bisogno di otto GPUs per rispondere in meno di un secondo a una singola domanda. Se considerate quante domande riceve un motore di ricerca potrete farvi un’idea dello sforzo hardware (e quindi energetico) che nutre la nostra curiosità.
Il secondo livello è il cloud computing. Ossia, in sostanza, l’ambiente digitale dove risiedono le informazioni, sia organizzate come servizi (modelli) che come contenuti (dati). La “nuvola” informatica consente di fatto a tutti di potersi connettere e utilizzare le funzionalità messe a disposizione dai produttori. Ci sono tre grandi modelli: (1) software as a service (SaaS); (2) platform as a service (PaaS); (3) infrastructure as a service (IaaS). Il primo mette a disposizione degli utenti un servizio specifico, ad esempio di streaming video. Il secondo mette a disposizione una piattaforma di servizi, ad esempio la suite di applicazioni di Google. Il terzo mette a disposizione una intera infrastruttura, ossia i computer e i dati dell’infrastruttura. L’IA ha bisogno di una cloud di questo tipo per poter essere diffusa.
Dentro la cloud, lo abbiamo detto, è necessario ci siano dei dati che l’IA deve elaborare per costruire le sue risposte. Entriamo così nel terzo livello della supply chain, quello dei training data. In pratica tutti ciò che il modello può digerire: video, foto, testi, suoni. Il grande brodo di coltura digitale dal quale si crede si possa estrarre una nuova vita, nel senso di pensiero originale.
Ed è in questa “estrazione” che interviene il quarto livello: quello dei foundations models. Si tratta di modelli di intelligenza artificiale che sono il cuore del prodotto finale. Avere dati di qualità e quantità sufficiente non basta a generar risposte valide se il modelli di fondazione hanno architetture inefficienti.
Infine, l’ultimo livello è quello a cui abbiamo accesso comune noi poveri mortali: il livello dell’applicazione. Quindi l’interfaccia attraverso la quale interagiamo con la macchina intelligente. I vari ChatGpt, Gemini, Claude, FInGPT, DALL-E, AlphaFold, Perplexity or GitHub Copilot.
Una volta che abbiamo compreso la filiera, si tratta adesso di vedere cosa incorpora. Ossia che realtà economiche si agitano dietro questa catena di montaggio. Ma ne parliamo alla prossima puntata.
(1/segue)
Cartolina. I chatbot siamo noi
Abbiamo paura delle macchine da quando abbiamo iniziato a costruirne. Temiamo l’innovazione, e tuttavia non riusciamo a farne a meno. Almeno da quando siamo diventati capaci di creare tecnologie. Vale per la ruota, il fuoco – pensate a quanto doveva spaventarci il fuoco, ci fa paura ancora oggi – , i telai meccanici e oggi l’intelligenza artificiale. Siamo scimmie vestite che hanno paura di ciò che indossano, perché temono di trasformarsi nel vestito. Lo spauracchio verso l’IA è solo la versione riveduta a corretta di quello che all’inizio del XIX si chiamava luddismo, e il fatto che gli ultra-miliardari firmino manifesti per invitare alla prudenza contro le macchine cosiddette intelligenti non è diverso da quando i Tudor inglesi vietavano le macchine per stampare fibbie. La paura è un sentimento democratico e trasversale. Esattamente come il coraggio. Il punto però non qui temere le macchine perché ci rubano il lavoro. Ciò che è davvero importante è capire che se abbiamo paura che un computer, che non fa altro che rimescolare idee e fatti noti, scriva meglio di noi un testo, una poesia, una musica o quello che volete voi, significa che abbiamo paura di non aver più nient’altro da dire. Nulla da aggiungere a ciò che è stato scritto, suonato, dipinto e, in sostanza immaginato. Ma in questo caso i bot saremmo noi. E’ di questo che abbiamo paura.
